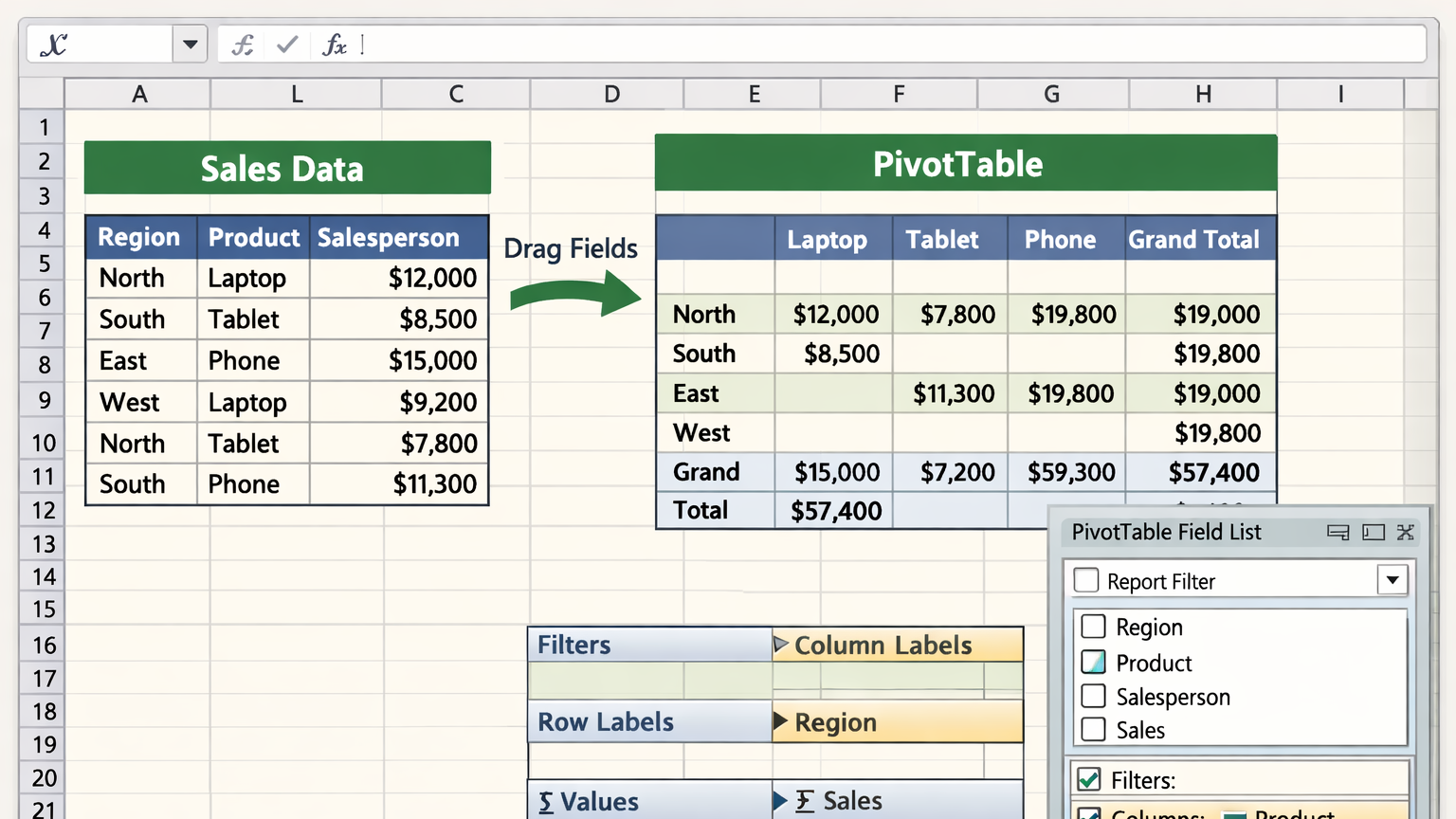
Pengenalan Machine Learning
Di tengah popularitasnya sebagai buzzword teknologi, Machine Learning (ML) sering kali dianggap sebagai subjek yang kompleks dan sulit dipahami. Seri artikel “Pengantar Machine Learning” ini disusun khusus untuk membantu pemula memahami esensi ML secara bertahap. Melalui lima bagian pembahasan, kita akan membedah konsep-konsep dasar secara lugas, didukung dengan detail krusial serta ilustrasi sederhana untuk memudahkan pemahaman tanpa membebani pembaca dengan teknis yang terlalu mendalam.
1. Apa itu Machine Learning?
Pada dasarnya, Machine Learning (ML) adalah bidang ilmu yang berfokus pada pengembangan algoritma agar komputer mampu melakukan prediksi atau menghasilkan konten (seperti teks, gambar, audio, dan video) tanpa diprogram secara eksplisit untuk setiap tugas tersebut. Kemampuan ini diperoleh melalui proses “belajar”, di mana mesin (komputer) dilatih untuk mengenali pola-pola kompleks di dalam sekumpulan data. Dari sinilah istilah machine learning atau pembelajaran mesin berasal.
Untuk memahami mekanisme kerja ML, kita dapat menggunakan analogi cara belajar pada anak-anak. Secara alamiah, seorang anak kecil belum mengetahui perbedaan antara hal-hal sederhana, seperti kucing dan anjing. Bagi orang dewasa hal ini tampak mudah, namun bagi seorang anak, diperlukan proses pembelajaran berulang sebelum ia mampu membedakannya.
Sebagai contoh, seorang anak memperhatikan kucing dan anjing melalui foto yang diperlihatkan orang dewasa. Orang dewasa kemudian menjelaskan mana yang termasuk kucing dan mana yang anjing. Dari penjelasan tersebut, sang anak secara tidak sadar menemukan pola; misalnya, ia menyimpulkan bahwa kucing memiliki telinga runcing atau bertubuh kecil. Setelah pola ini terbentuk, ia dapat menentukan sendiri foto hewan yang baru dilihatnya. Namun, karena informasi yang dimiliki masih terbatas, kesalahan identifikasi tetap bisa terjadi. Jika anak tersebut melihat serigala, ia mungkin mengiranya sebagai anjing karena kemiripan bentuknya. Sebaliknya, saat melihat anjing jenis Chihuahua, ia mungkin salah mengira itu adalah kucing karena ukurannya yang kecil.
Prinsip yang sama berlaku pada model yang Anda latih dalam machine learning. Dalam analogi tersebut, mesin berperan sebagai “anak” yang belajar, sementara Anda berperan sebagai “orang dewasa” yang menyediakan informasi (data). Model yang terbentuk setelah proses pelatihan pada dasarnya bekerja dengan memetakan pola dari data yang Anda suguhkan.
Tentu saja, keakuratan model tersebut sangat bergantung pada kualitas data tersebut. Hal ini mencakup beberapa faktor krusial, seperti: apakah volume informasi yang tersedia sudah mencukupi, apakah data tersebut sudah cukup bervariasi untuk mencakup berbagai kemungkinan kasus di lapangan, dan seterusnya. Inilah esensi dari machine learning.
Untuk merangkum konsep ini secara ilmiah, kita dapat merujuk pada definisi formal dari Tom Mitchell (1997):
“Sebuah program komputer dikatakan belajar dari pengalaman E terkait dengan suatu tugas T dan ukuran kinerja P, jika kinerjanya pada T, yang diukur dengan P, meningkat seiring dengan bertambahnya pengalaman E.”
Jika dikaitkan dengan analogi sebelumnya, maka yang dimaksud oleh Tom Mitchell adalah: sebuah program komputer dikatakan “belajar” jika kemampuannya dalam membedakan foto kucing dan anjing (T/Task) meningkat seiring dengan bertambahnya jumlah foto yang dipelajari (E/Experience). Peningkatan ini diukur menggunakan nilai tertentu seperti akurasi (P/performance).
2. ML vs Pemrograman Konvensional
Perbedaan mendasar antara pemrograman konvensional dan Machine Learning terletak pada siapa yang bertanggung jawab dalam merumuskan logika atau aturan untuk menyelesaikan suatu masalah.
Pada pemrograman konvensional, seorang programmer harus memahami logika masalah secara menyeluruh dan menuliskan aturan tersebut secara eksplisit dalam bentuk kode.
DATA + ATURAN (Logika buatan manusia) → OUTPUTKomputer bertindak sebagai pelaksana instruksi yang kaku. Jika ada skenario yang tidak didefinisikan dalam aturan oleh programmer, komputer tidak akan tahu apa yang harus dilakukan.
Sebaliknya, pada Machine Learning, programmer tidak memberi tahu komputer aturannya. Programmer justru memberikan contoh data beserta jawaban yang benar (label), lalu membiarkan algoritma menemukan sendiri hubungan atau pola di antara keduanya.
DATA + OUTPUT (Target/Jawaban) → ATURAN (Model hasil pembelajaran)Proses ini menghasilkan sebuah Model. Model inilah yang nantinya digunakan untuk memproses data baru yang belum pernah dilihat sebelumnya untuk memberikan prediksi.
Sebagai ilustrasi, misalkan seorang programmer ingin membuat program untuk mendeteksi email spam. Gambar berikut ini mengilustrasikan dua pendekatan yang dapat dilakukan.

Jika menggunakan pemrograman konvensional, seorang programmer harus mendefinisikan semua kemungkinan kata kunci (keywords) yang mungkin termuat di dalam email spam. Dalam kasus ini, pendekatan konvensional tentu saja kurang ideal, sebab jenis dan trik email spam terus berkembang. Sebaliknya, dengan ML, seorang programmer hanya perlu menyediakan kumpulan email yang sudah dilabeli (spam/bukan spam), kemudian membiarkan model menemukan polanya sendiri.
Meskipun begitu, penting untuk dicatat bahwa Machine Learning bukanlah pengganti pemrograman konvensional. Keduanya memiliki domain penggunaan masing-masing. Misalnya, program konversi suhu dari Fahrenheit ke Celsius tidak perlu menggunakan ML, karena aturan matematisnya sudah pasti dan baku.
# Ilustrasi sederhana: filosofi aturan manual vs belajar dari data
# Tidak ada library ML di sini ini hanya untuk memperlihatkan perbedaan cara berpikir
# ============================================================
# PENDEKATAN KONVENSIONAL: Aturan ditulis manual oleh programmer
# ============================================================
def deteksi_spam_manual(email: str) -> str:
email = email.lower()
if "menang hadiah" in email:
return "SPAM"
elif "klik link ini" in email:
return "SPAM"
elif "transfer uang" in email:
return "SPAM"
return "BUKAN SPAM"
print("=== Pendekatan Konvensional (aturan manual) ===")
print(deteksi_spam_manual("Selamat! Anda menang hadiah 10 juta.")) # → SPAM
print(deteksi_spam_manual("Rapat tim besok jam 10 pagi.")) # → BUKAN SPAM
print(deteksi_spam_manual("Penawaran eksklusif hanya hari ini!")) # → BUKAN SPAM ❌ (lolos!)
print()
print("=== Pendekatan Machine Learning (konseptual) ===")
print("""
# Kita TIDAK menulis aturan. Kita menyiapkan data berlabel:
#
# data_latih = [
# ("Selamat Anda menang hadiah!", "SPAM"),
# ("Penawaran eksklusif hari ini!", "SPAM"),
# ("Rapat besok jam 10", "BUKAN SPAM"),
# ... (ribuan contoh lagi) ...
# ]
#
# model = train(data_latih) ← komputer menemukan aturannya sendiri
# model.predict("Email baru") ← bisa mengenali pola yang belum pernah dilihat
""")=== Pendekatan Konvensional (aturan manual) ===
SPAM
BUKAN SPAM
BUKAN SPAM
=== Pendekatan Machine Learning (konseptual) ===
# Kita TIDAK menulis aturan. Kita menyiapkan data berlabel:
#
# data_latih = [
# ("Selamat Anda menang hadiah!", "SPAM"),
# ("Penawaran eksklusif hari ini!", "SPAM"),
# ("Rapat besok jam 10", "BUKAN SPAM"),
# ... (ribuan contoh lagi) ...
# ]
#
# model = train(data_latih) ← komputer menemukan aturannya sendiri
# model.predict("Email baru") ← bisa mengenali pola yang belum pernah dilihat
3. Mengapa ML Dibutuhkan dalam Sains Data?
Sains data (Data Science) bertujuan untuk mengekstraksi wawasan (insights) dan nilai dari sekumpulan data. Namun, seiring dengan kompleksitas masalah dan volume data yang terus membengkak, pendekatan analitik dan pemrograman konvensional sering kali menemui jalan buntu. Dalam konteks inilah ML bertindak sebagai mesin penggerak utama.
Secara umum, terdapat empat situasi krusial di mana ML jauh lebih unggul dan esensial dibandingkan pendekatan pemrograman konvensional:
3.1 Pemecahan Masalah yang Terlalu Kompleks untuk Dirumuskan Secara Eksplisit
Mengembangkan aturan manual untuk tugas-tugas perseptual, seperti pengenalan wajah manusia, hampir mustahil dilakukan. Bayangkan jika seorang programmer harus menulis kode untuk mendefinisikan bentuk mata atau hidung berdasarkan nilai piksel. Bagaimana jika wajah subjek miring 30 derajat? Bagaimana jika pencahayaan ruangan redup, resolusi kamera rendah, atau subjek mengenakan kacamata?
Pendekatan konvensional akan membutuhkan jutaan baris kode if-then yang rumit, dan sistem tersebut tetap akan rentan gagal hanya karena sedikit perubahan pada gambar. Sebaliknya, ML mengatasi hal ini dengan mempelajari fitur-fitur visual secara mandiri langsung dari ribuan atau jutaan contoh foto, tanpa perlu aturan geometris yang didefinisikan satu per satu oleh manusia.
3.2 Adaptasi Terhadap Pola yang Berubah Seiring Waktu
Dalam dunia nyata, data dan tren jarang bersifat statis; mereka dinamis dan terus berkembang. Contoh klasiknya adalah sistem deteksi penipuan (fraud detection) pada transaksi perbankan atau kartu kredit. Pelaku kejahatan siber terus-menerus mencari celah baru dan mengubah taktik mereka.
Jika mengandalkan pemrograman konvensional, aturan keamanan yang ditulis hari ini mungkin akan usang dan mudah ditembus pada bulan depan. Sebaliknya, model ML dirancang untuk beradaptasi. Model tersebut dapat dievaluasi dan dilatih ulang (retraining) secara berkala menggunakan data transaksi terbaru. Dengan demikian, sistem dapat terus mengimbangi pola penipuan yang baru secara efisien tanpa harus merombak seluruh kode program dari awal.
3.3 Penanganan Skala Data yang Mustahil Dianalisis Manual
Di era digital saat ini, volume data yang dihasilkan sangat masif. Secara kognitif, manusia tidak memiliki kapasitas untuk membaca, memproses, apalagi menemukan korelasi tersembunyi dari puluhan juta baris data, misalnya pada jutaan rekam medis pasien di sebuah rumah sakit nasional.
Machine Learning memiliki kemampuan komputasi untuk menganalisis kumpulan data berdimensi tinggi (high-dimensional data) dalam skala yang ekstrem. Melalui algoritma ML, kita dapat mengekstraksi wawasan berharga, menemukan tren jangka panjang, dan bahkan memprediksi risiko penyakit yang polanya terlalu rumit dan tidak kasat mata bagi analis manusia.
3.4 Personalisasi dalam Skala Masif
Model bisnis digital modern sangat bergantung pada pengalaman pengguna yang disesuaikan secara personal (tailored experience). Platform seperti Netflix, Spotify, atau situs e-commerce memberikan rekomendasi konten maupun produk yang berbeda-beda untuk setiap penggunanya.
Menulis aturan manual untuk melayani preferensi ratusan juta pengguna secara real-time adalah hal yang tidak rasional secara teknis. ML memecahkan masalah ini melalui sistem rekomendasi (recommender systems). Algoritma akan mempelajari riwayat interaksi setiap pengguna secara individual, membandingkannya dengan miliaran titik data lain, dan memprediksi apa yang paling relevan bagi pengguna tersebut. Hasilnya adalah personalisasi tingkat tinggi dalam skala masif yang berjalan secara otomatis.
4. Anatomi Pipeline Machine Learning
Dalam praktiknya, ML bukan sekadar tentang algoritma, melainkan sebuah proses panjang. Pipeline ML merujuk pada alur kerja menyeluruh (end-to-end), dimulai dari penanganan data mentah hingga menghasilkan model yang siap digunakan di dunia nyata.
Berikut adalah gambaran alur kerja tersebut: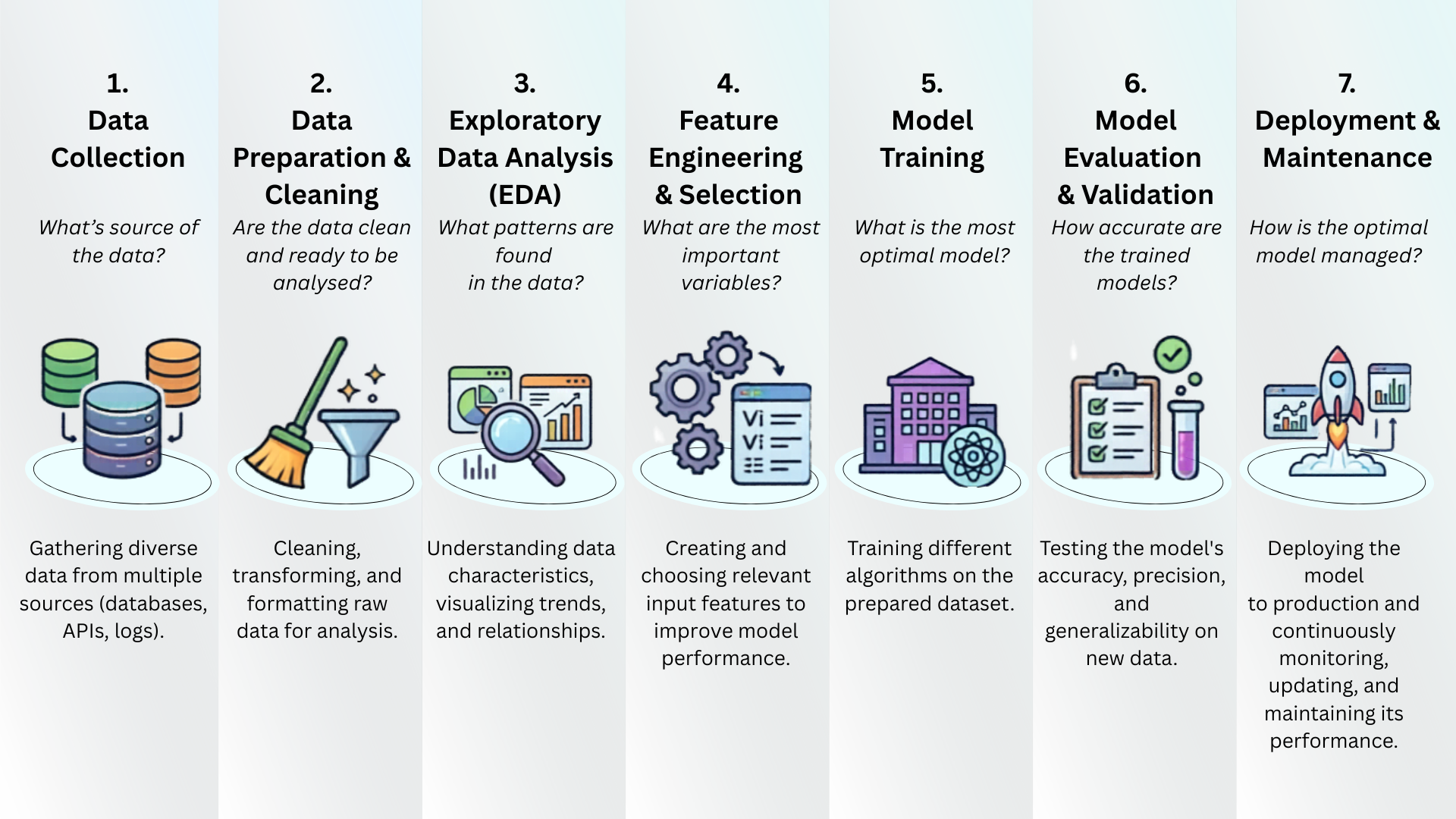
Tahap 1: Pengumpulan Data (Data Collection)
Data adalah bahan bakar utama bagi Machine Learning. Sumber data dapat sangat bervariasi, mulai dari formulir survei, sensor Internet of Things (IoT), database internal perusahaan, API publik, hingga ekstraksi data dari situs web (web scraping). Terdapat sebuah prinsip fundamental di tahap ini: “Garbage in, garbage out”. Artinya, secanggih apa pun algoritma yang digunakan, kualitas dan akurasi model bergantung sepenuhnya pada kualitas data yang dikumpulkan.
Tahap 2: Pra-pemrosesan Data (Preprocessing Data)
Di dunia nyata, data mentah hampir selalu dalam keadaan “kotor” dan tidak beraturan. Data tersebut mungkin memiliki nilai yang kosong (missing values), format yang tidak konsisten, atau memuat kolom yang tidak relevan dengan masalah yang ingin dipecahkan. Tahap ini sangat krusial dan umumnya mencakup:
- Pembersihan data (data cleaning): Mengisi atau menghapus data yang kosong/hilang.
- Normalisasi: Menyamakan skala angka agar nilai yang sangat besar tidak mendominasi proses pembelajaran.
- Encoding: Mengubah data kategorikal (berupa teks, seperti “Pria” atau “Wanita”) menjadi angka agar dapat diproses oleh algoritma matematis.
- Seleksi fitur (Feature Selection): Memilih atribut data yang paling relevan untuk melatih model.
Tahap 3: Pelatihan Model (Training)
Pada tahap ini, data yang sudah bersih “disuapkan” ke dalam algoritma Machine Learning. Model akan mulai mengekstraksi dan mempelajari pola yang tersembunyi di dalam data latih tersebut. Proses komputasi ini bisa berlangsung sangat cepat (dalam hitungan detik) hingga sangat lama (berminggu-minggu), bergantung pada seberapa besar volume data dan seberapa kompleks algoritma yang digunakan.
Tahap 4: Evaluasi dan Validasi (Evaluation and Validation)
Setelah model selesai dilatih, kita tidak bisa langsung mempercayai hasilnya. Model harus diuji menggunakan data baru yang belum pernah dilihat sebelumnya untuk mengukur performa dan akurasinya di dunia nyata. Jika model memberikan hasil sempurna pada data latih namun gagal total saat diberikan data baru, model tersebut mengalami overfitting, sebuah kondisi dimana seolah-olah model hanya “menghafal” jawaban dari data latih tanpa benar-benar memahami polanya. Ini adalah salah satu jebakan paling umum dalam ML.
Tahap 5: Deployment
Setelah model lolos uji evaluasi akhir dan tervalidasi dengan baik, model siap diintegrasikan ke dalam sistem perangkat lunak yang sesungguhnya. Bentuk penerapannya bisa berupa layanan REST API, fitur pintar di dalam aplikasi mobile, atau sistem rekomendasi real-time yang langsung berinteraksi dengan pengguna akhir.
Catatan penting: Pipeline ini tidak selalu linear. Dalam praktiknya, kita sering kembali ke tahap sebelumnya. Evaluasi yang buruk bisa berarti kita perlu mengumpulkan lebih banyak data, memperbaiki preprocessing, atau mengganti algoritma.
5. Jenis-jenis Data dalam ML
Dalam Machine Learning, data adalah fondasi utama. Namun, tidak semua data diciptakan sama. Cara kita memproses dan memilih algoritma sangat bergantung pada jenis data yang kita miliki. Secara garis besar, data terbagi berdasarkan strukturnya dan format spesifiknya.
5.1 Data Terstruktur vs Tidak Terstruktur
Secara konseptual, data di dunia nyata terbagi menjadi dua kategori utama berdasarkan tingkat keteraturannya, yaitu data terstruktur (structured data) dan data tidak terstruktur (unstructured data).
Data terstruktur adalah informasi yang telah diorganisasikan ke dalam format baku yang dapat diprediksi, umumnya berupa tabel dengan baris dan kolom yang jelas. Kerapian ini membuat data terstruktur sangat mudah diolah, dicari, dan dianalisis menggunakan algoritma ML standar. Sebaliknya, data tidak terstruktur adalah informasi mentah yang tidak mengikuti model organisasional apa pun, misalnya foto, rekaman suara, teks bebas, atau video. Karena bentuknya yang kompleks dan bebas, komputer tidak dapat langsung memprosesnya. Oleh karena itu, kita membutuhkan teknik Machine Learning yang lebih canggih untuk mengekstraksi fitur dan menemukan makna tersembunyi dari data tidak terstruktur tersebut.
5.2 Tipe-tipe Data dalam ML
Selain strukturnya, data juga diklasifikasikan berdasarkan format atau sifat informasinya:
5.2.1 Data Tabel (Tabular)
Data tabular adalah data yang disusun dalam format dua dimensi (baris dan kolom). Setiap baris mewakili satu observasi atau entitas, dan setiap kolom mewakili atribut atau fitur dari entitas tersebut.
Data titanic merupakan data tabular dimana setiap baris merepresentasikan penumpang kapal titanic, dan setiap kolom merepresentasikan karakteristik tiap penumpang. Tugas utama pada data ini adalah untuk memprediksi penumpang mana yang selamat dari tragedi Titanic berdasarkan data seperti umur, jenis kelamin, dan kelas tiket.
5.2.2 Data Deret Waktu (Time Series)
Data deret waktu adalah urutan titik data yang dicatat pada interval waktu tertentu. Dalam tipe data ini, urutan kronologis sangat krusial dan tidak boleh diacak, karena informasi utamanya terletak pada tren atau perubahan dari waktu ke waktu.
Data store sales merupakan contoh data time series, di mana tiap baris merepresentasikan tanggal/waktu. Tujuan utama dari data ini adalah menggunakan data riwayat penjualan harian dari sebuah jaringan supermarket untuk memprediksi tingkat penjualan produk di masa depan.
5.2.3 Data Teks (Text)
Data teks merujuk pada informasi dalam bentuk bahasa alami manusia, seperti surel (email), artikel berita, ulasan pelanggan, hingga kode program. Karena komputer tidak memahami makna semantik kata, teks harus diproses dan diubah menjadi representasi numerik sebelum dapat dianalisis.
Data IMDBberisi 50.000 ulasan film dari platform IMDB. Kasus penggunaannya adalah Natural Language Processing (NLP) untuk menganalisis sentimen, yaitu analisis untuk menentukan apakah sebuah ulasan teks memiliki nada positif atau negatif.
5.2.4 Data Gambar (Image)
Seperti yang telah dibahas pada bagian matematika, komputer tidak memproses gambar secara visual. Sebuah gambar pada dasarnya diproses sebagai matriks (kumpulan angka) yang mewakili nilai intensitas piksel. Gambar berwarna umumnya memiliki tiga lapisan matriks: merah, hijau, dan biru (RGB).
Salah satu contoh kasusnya adalah data dogs vs cats, diambil dari sebuah kompetisi Kaggle yang menantang peserta untuk melatih model yang dapat mengklasifikasikan apakah sebuah gambar berisi seekor anjing atau seekor kucing.
5.2.5 Data Suara (Audio)
Data audio berupa gelombang suara analog yang didigitalisasi menjadi serangkaian nilai numerik yang berubah-ubah seiring waktu (merepresentasikan amplitudo dan frekuensi).
Data GTZAN merupakan salah satu referensi standar untuk pemrosesan audio. Alih-alih memberikan rekaman suara mentah, dataset ini telah mengekstrak fitur-fitur akustik dari ribuan lagu dan menyajikannya dalam format tabel (CSV) untuk melatih model agar mampu mengklasifikasikan 10 genre musik yang berbeda (seperti jazz, rock, pop, dll).